
The Art of Developing for LLM Users
Engineering in 2025

As we enter 2025, LLMs have demonstrated remarkable capabilities, matching or surpassing human performance across scientific research [1], coding tasks [2], or even general problem-solving [3]. While some view this as a threat to software engineering jobs, I see it differently – our role isn't diminishing, it's expanding into
designing for usability of a strange new user, an LLM.
For the past year, I’ve been helping write software to use LLMs for science at FutureHouse [4, 5]. We are approaching tasks in which scale and automation are bottlenecks to research and using models to provide the automation needed for discoveries. These could be latent in the literature, or wholly new syntheses from mixtures of simulations, literature reviews and automated experiments. These sorts of tasks are iterative, open-ended, nonlinear, and even for expert humans, pretty difficult. The nature of this work – iterative, open-ended, and nonlinear – demands that LLMs have the capability to make decisions, thus becoming users themselves.
Lots of tasks exist in this category, like writing code [6], role-playing as a character [7], or aiding as a personal assistant [8]. The capability to successfully approach these problems is causing a trend in software, as evidenced by the proliferation of new frameworks [9, 10, 11, 12, 13]. These libraries center on the concept of framing an LLM as an “agent”. The LLM agents, when given a task, orchestrate the use of tools (i.e. functions and input arguments) to successfully complete a user-specified task. Pragmatically, this is achieved by combining some key info into a prompt: each potential function and argument list, a task preamble, and an appended history of function calls. The prompt simply asks the LLM to specify the next function call, along with input arguments. You loop until some prompted condition is met or you reach a hard coded condition. Voilà, you’ve got an LLM agent, and from a software engineer’s standpoint, a new user.
There are a litany of approaches to improve an LLM agent, like adding in explicit reasoning steps [14, 15], iteratively re-training (or fine-tuning) on high-performing task-specific datasets [16,17], or increasing test-time inference to see higher performance [18]. These are means of making our LLM user smarter, and an interesting option in our toolset, but no matter the application, we still need to write some “traditional” software for the LLM to actually execute. Here, the essence of the development remains the same, our goal is to define a task in terms of functions, arguments, and documentation (prompt for LLMs), then tweak our system to best achieve some test metric (often benchmark performance for LLMs).
Engineering Workflows for LLM Users
So what’s different about designing for LLM agent users? No matter if we add or remove tools, build retrieval-based features, or use prompt-engineering, we’re conditioning our agent LLM’s output in an attempt to improve some task’s performance. We start with a well defined tasks with a measurable outcome (as I suppose we should with anything). Then we can quantitatively track outcomes and changes in our tool function definitions or tool choices. Just as traditional app development is driven by experimentally validated AB testing, changes to code executed by our LLM agents are driven by task evaluations. We can measure the percentage of correctly completed tasks as our metric, and, as engineers, we focus on modifying our system to maximize our success percentage.
As a concrete example, let’s imagine building an experiment protocol writing LLM agent. For our tasks, we have a list 100 statements like:
I have the following hypothesis: "The relationship between carbon content (0.1-1.0%) and tensile strength in plain carbon steel exhibits a peak, with strength degradation above and below an optimal concentration due to microstructural changes in the ferrite-cementite phases", write a detailed lab protocol to test this hypothesis.
Each result can then be graded by materials scientists based on two binary factors: 1. Being complete enough to actually execute, and 2. A valid examination of the hypothesis in question. If the LLM agent’s output passes both factors, then we would evaluate that task as a success. We could run all 100 statements, and measure the percentage of the statements that our agent succeeded. Let’s walk through 4 engineering scenarios as we build our protocol agent.
Zero-shot scenario
We start with the simplest scenario, where we prompt our LLM agent with each statement directly, no tools or additional prompting are specified. We write a function to make an inference API call to a frontier model provider, along with some simple error handling, and return the result text directly. This is the zero-shot scenario, where the model is expected to complete the task without any structured prompt manipulations. Everything is left to the user, the agent LLM. Because LLMs know some chemistry [19], we expect to see a little success here. Let’s say that, after grading, 7% of our protocols are evaluated positively. Not too shabby since we wrote one tiny function. We’re relying on our user pretty heavily here, but we had to try it.
Simple RAG tool scenario
Let’s use some prior intuition for tools that the LLM user may need. It seems likely that a keyword search for existing experimental protocols would help make new protocols. So, we build a new function for our agent to orchestrate, a protocol search tool. This tool takes in a protocol query string, then does a full-text search on a database of existing protocols, returning the top 5 most relevant items. Our function injects the content of these protocols into a prompt which asks an LLM to make a new protocol satisfying the user’s initial request. Our function returns the proposed protocol text to the agent LLM, who can make a decision on making another query to our new tool or terminating the workflow given the current protocol. We now have genuine decisions being made by our agent, query selection and protocol evaluation, but we have to provision resources like a database with full-text search. Not to mention building a pipeline to populate this database. Lots of engineering work for our user!
Now that we’ve implemented our tool (really just a simple RAG [20] function), let’s call this version of our agent simple RAG. We’re again able to run our task across 100 protocol requests, and check our success rate as evaluated by our crack team of materials scientists. Let’s imagine that our tool helped our user, and we now see 29% success, nice.
RAG + Code tool scenario
We’re on a roll, so let’s take the simple RAG version and add another tool, which writes PyLabRobot code [21] for the proposed procedure with explanatory comments. Maybe the tool includes PyLabRobot’s documentation as part of its prompting. This provides the agent model with an ability to be more precise in its lab protocols. After adding this tool, the agent can now make an initial call to the protocol search tool, then refine it with a call to our PyLabRobot tool. Our agent then receives the PyLabRobot code, and inserts it into the existing protocol. The higher specificity of our code-injected responses increases our task performance to 40%, holy smokes. We call this version of our pipeline: RAG + code.
If we think about what we’ve done in terms of this additional tool, we have expanded the agent model’s opportunity to use reasoning to improve its protocol. Our prior tool, which was based on existing text-based lab protocols, overly prescribed our problem and didn’t provide the agent an explicit opportunity to add code. Adding our code tool allowed the agent to have a greater diversity of token sequences in its trajectory. Since we saw an increase in task performance when we added our new tool, we can consider simple RAG to be freedom bound relative to RAG + code, where additional freedom was able to be utilized for higher performance.
Tool freedom scenario
What if we decide that we don’t want freedom to be an issue at all – thus we provide tools that are far more basic, and flexible. We could provide one tool, which simply runs code written by the LLM agent user in a bash shell. The input of the tool could be the code, filename, and bash command. This tool would be extremely flexible, and in principle, would allow the agent to recreate both tools we’ve built in RAG + code. This gives the agent user a lot of freedom, the available token sequence space to the agent is vastly increased (almost to the same extent as the zero-shot scenario).
However, with this freedom-forward toolset, we may see a decrease in performance relative to RAG + code, down to 25% success. The agent wasn’t smart enough to recreate tools in the same way that our intuitions guided us. In this case, which we can call tool freedom, the agent was reasoning bound rather than freedom bound.
The Art of Developing for LLM Users
These four test scenarios, zero-shot, tool freedom, RAG + code, and simple RAG create a spectrum of flexibility in terms of agent model token sequence selection space. As we traverse between each of these scenarios, we’re allowing/biasing our agent LLM model to utilize a smaller accessible region in token-sequence space. The largest region, zero-shot, is where there are absolutely no restrictions on the model output, and in simple RAG we have essentially just the valid inputs for one tool. This is analogous to having a platform that allows users to deploy their own website code vs. providing a no-code GUI.
Let’s visualize this — we can choose some metric representing the level of restriction on the agent token sequence space, i.e. the inverse of the observed agent token sequence entropy, and plot each scenario against our measured task performance. (Note: this is likely explicitly measurable via sampling token sequence entropy in our task, but here we’ll just guesstimate for our visualization) We immediately see regions before and after the performance maximum, before the maximum, we’re in our reasoning bound region, where the model isn’t smart enough to make use of the tools it’s been given. After the maximum, it’s a freedom bound region, where the model is too constrained to make use of its abilities.
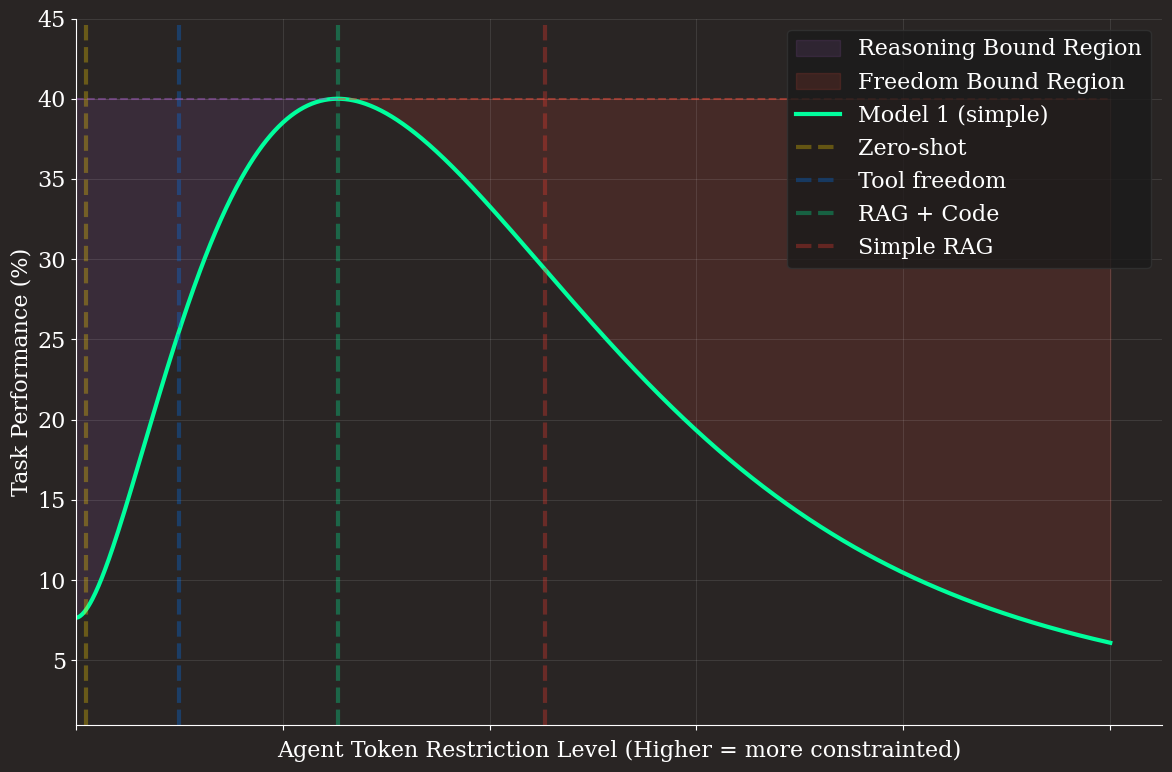
This model is pretty idealized, as linear interpolation in this token space is likely to be incoherent. Though we can imagine some scheme of non-gradient based updates in which small modulations are made on our toolset until we smoothly transition from zero-shot to tool freedom to RAG + code to simple RAG. This obviously won’t be a complete exploration of the space, and surely isn’t a global maximum, but I hypothesize that, for a fixed agent model, across any spectrum of functions, you’ll see a similar trend with a “peak” in token restriction space.
Thus the task of an engineer developing for LLM users becomes marching up this curve, either working towards restricting token space in the reasoning bound scenario or increasing flexibility in the freedom bound scenario. Because the space is radically non-linear, this is a difficult optimization problem where prior intuition is difficult to build. It will take lots of task-specific experimentation. This is the art of developing for LLM users. It follows a familiar philosophy for human users, “Everything should be made as simple as possible, but no simpler”, with some differences:
1. We don’t know our LLM user’s capabilities beforehand for most tasks (maybe we can just ask).
2. LLM users have more capacity for complexity scaling and context switching. Our application can mix simple functions with with functions that require code-writing or mathematical formalisms as inputs, they don’t mind.
3. We can more easily “train” LLM users, changing their capabilities.
4. LLM user actions directly add costs to our application’s runtime, and, the smarter the LLM, the higher the cost.
Differences 1 and 2 reinforce the need for experimentation as detailed above, 3 and 4 change the market dynamics of developing for LLMs. Let’s dig into these dynamics.
But these LLM users evolve, how do we?
The above analysis assumes a “fixed” agent model. What about fine tuning, new models, or re-training for more test-time inference (i.e. OpenAI’s o1 strategy)? My contention is that these steps, when successful, will shift and sharpen the task performance curves on the token restriction space graphs. Let’s imagine four models, each with a better task performance than the last, one which is our base/frontier model from the prior section (model 1), another which is the same model fine-tuned for the task at hand (model 2), a third where the agent model is additionally trained to execute long-form train of thought with more test-time inference (model 3), and a fourth, which is a radically larger “genius model” (model 4). We’ve plotted the task performance vs. token restriction plot below.
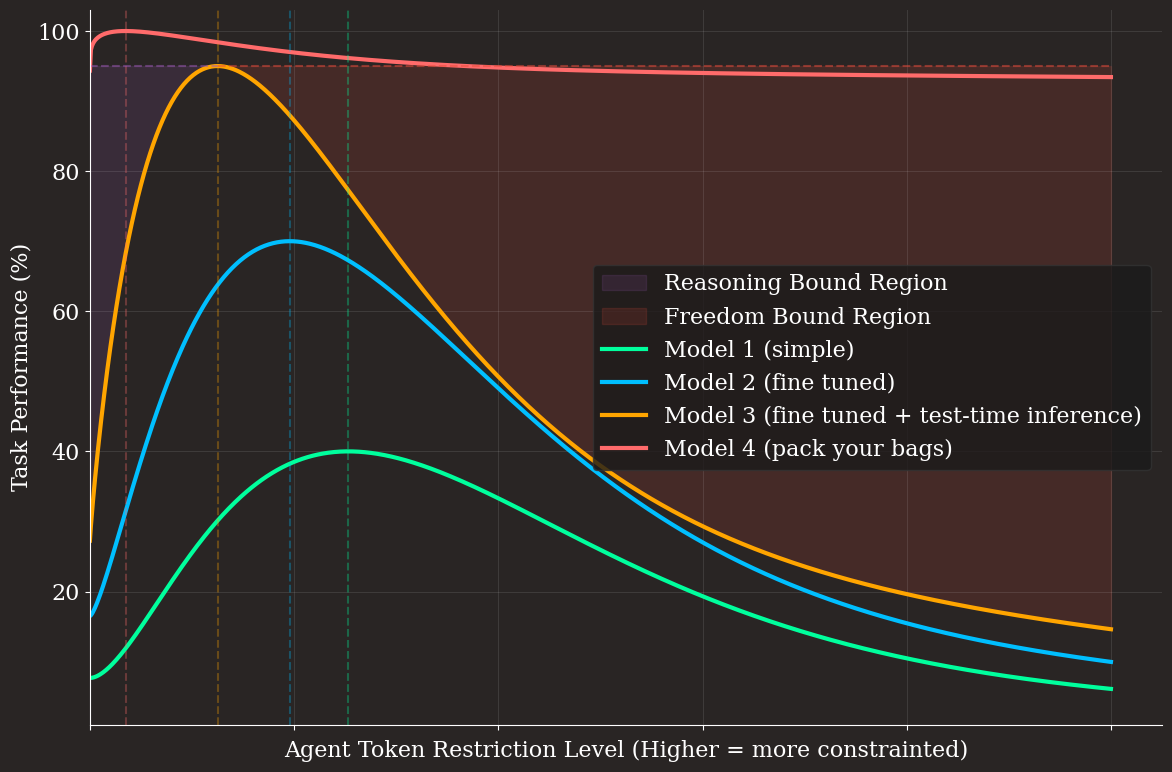
We can see with each smarter iteration of the model, less token restriction is necessary, and the reasoning bound regions shrink. This translates to less work for engineers in experimentally trudging up and down the task performance curve via experimental updates with differing levels of token limitations, and more work in gathering training data or optimization training infrastructure code. Let’s look at how we might characterize the engineering workflows across each of our modeling scenarios:
Model 1 – Simple, Relying on existing frontier models
Engineering may initially focus on working to deeply understand the domain problem (same as pre-LLM based development), then writing, testing, and deploying LLM tools which reflect appropriate units of work for each domain:
Optimizing tool and argument description prompts. (better documentation)
Provisioning and populating database technologies to assist in retrieval for tools.
Measurable and scalable deployments to handle the high inference volume needed by iterative experimentation.
Configuring or building experimentation frameworks to measure and iterate on task performance.
Designing and building UI to support visualizing LLM agent decision making and delivering human feedback where necessary.
These steps all look pretty familiar relative to traditional web development platforms. One notable difference being that your “documentation” is read an utilized by an LLM agent, and you’ll need to write it as such. You can talk about avoiding hallucinations or the number of r’s in strawberry — stuff that humans won’t need. It’s worth noting that backend and frontend engineers without lots of “AI” knowledge can be utilized across all of these workflows.
Models 2,3 – Scaling up training
Engineering efforts focus more deeply on data generation and model training, ideally allowing for the usage of a more generalized toolset, removing some burden in tightly mapping a problem domain to a toolset. The engineering tasks used for Model 1 are still relevant, with a couple of major new workflows for trained models:
Distributed training infrastructure, GPUs, hardware optimizations, the whole MLE gamut.
Scaling up data generation, could be via developing a platform with a large user-base to get expert-human data, or through identifying optimal LLM agent trajectories among a large volume of attempted tasks.
Here’s where hiring gets trickier as these tasks are more math-y than the model 1 scenario. Luckily organizations already employ machine learning engineers to transform their data into models which aid users, so these are a fungible skills. Like human users, LLM agents can bootstrap themselves into becoming smarter users of your code, but unlike human users, the training costs can be quite high. Engineers need to be judicious about their data collection and training to make their agents cost effective.
Model 4
Of course, model 4, is a special “pack your bags” scenario, where once trained, there’s little engineering work to be done, as given only basic tools, a model of this caliber will be able to complete challenging tasks from scratch. At this point our LLM user simultaneously becomes a developer. This sort of model would likely have a very similar toolset between tasks, and the work would be very “platform” level. For example, it likely needs a tool to authorize payments for infrastructure provisioning or to run its code inside of a VM. Assuming a sufficiently commoditized platform exists for the “pack your bags” model, this scenario would represent a down-tick in work for engineers. We aren’t here yet across basically any non-trivial task I can find, and we’ve also not yet considered cost, which changes our performance curve pretty dramatically.
How does money change things?
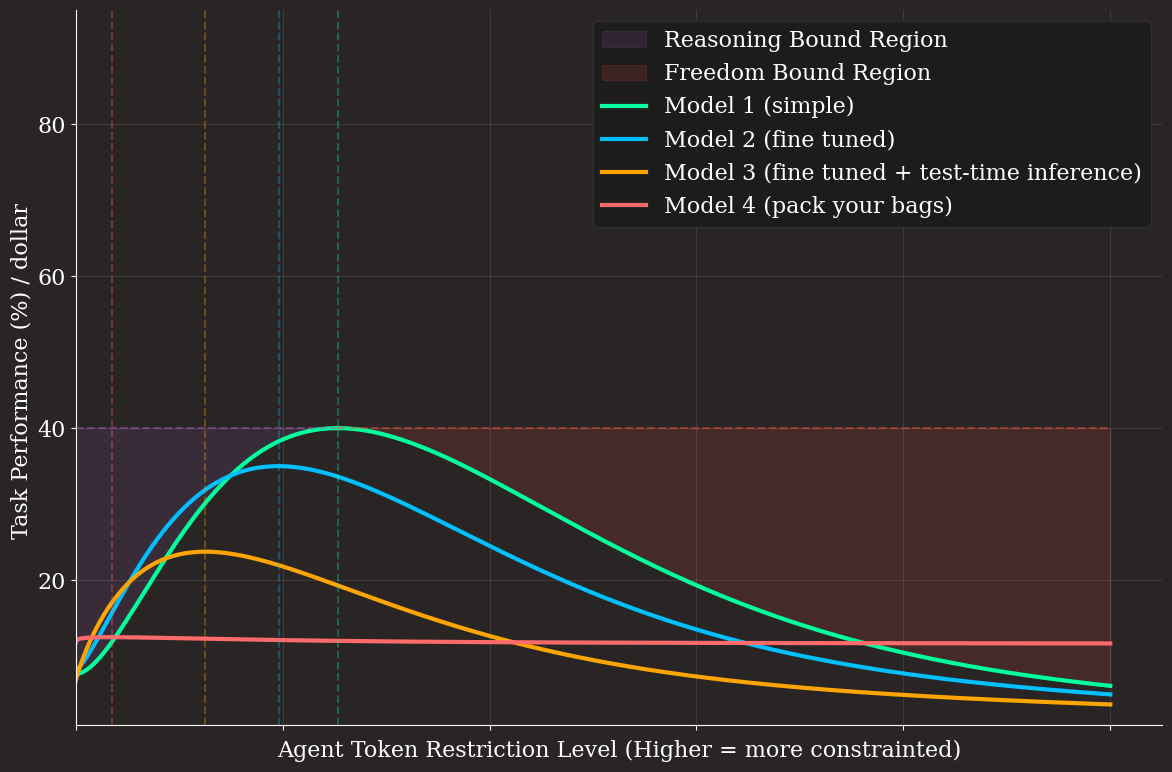
The average all-in inference cost across each of our hypothetical Model 1-4 scenarios is difficult to model. Models 2 and 3 include a lot of extra upfront compute and developer costs, and while Model 2 may have a similar run-time inference cost as Model 1, Model 3 includes a significant increase in run-time inference costs. Model 4 includes some theoretical breakthroughs which don’t yet exist, so the cost scaling of a “pack your bags” model is even more uncertain.
One very simple assumption is that our inference costs double between each model iteration (i.e. model 1 = 1x and model 4 = 8x). We’re assuming that the developer or human export-scoring costs are baked into this simple cost scaling. While this sort of projection is overly broad, the point is that an exponential scaling of costs and diminishing returns on performance can produce scenarios where commodity frontier models with lots of tweaks and domain-specific tools could have a better cost efficiency than more complex models.
The inference cost sensitivity is radically different among domains. Taking an agent that makes book recommendations as an example, inference costs would need to be very low for ad revenue to cover the cost. However, if our domain was developing a new cancer drug, then we will be far less sensitive to costs. I imagine the market will optimize itself towards each task.
This bodes well for the future of employment for engineers, as I suspect that there are nearly infinite pockets of valuable, but highly-cost sensitive tasks where a “middling” model intelligence would provide significant benefit, but only with significant tooling. I think this is a funny trade-off in terms of LLM users, smart users are more expensive, so dumber users with lots of help make sense for many applications.
Conclusions
There certainly exists a paradigm shifting “pack your bags” scenario, where a hyper-capable and relatively low cost model emerges. As engineers, we’d only need to provide a tiny bit of tooling, and this AGI-user would take it from there. As it stands now, models aren’t performant enough to handle the reasoning overhead necessary to bootstrap their own agentic tools, and the highest performing reasoning systems [3] are exponentially more expensive than “basal” LLM inference. So we’re stuck developing for slightly-less-intelligent models.
In absence of a radical improvement in cost scaling for the same levels of reasoning capabilities, LLMs as they exist now still have tremendous potential to help in complex domains, albeit with significant optimization efforts from engineers. The art of developing for these tasks becomes writing code which threads the complexity needle – flexible enough to provide LLMs freedom to explore and constrained enough to avoid consistent reasoning failures. This is an iterative and code-heavy process.
While the toy model included here is overly simplified, it helps me think about where the future is going. I think we are going to see an increased demand for agentic LLM-based software, and, without a fundamental shift in performance per dollar, engineers are going to have a lot of optimizing to do in marching up these task performance curves. I suspect commodity products will emerge (or be modified from existing platforms) which help lower the barrier to these agentic LLM workflows, but implementing these solutions will still take expertise–a lot of it.